AI金融助手
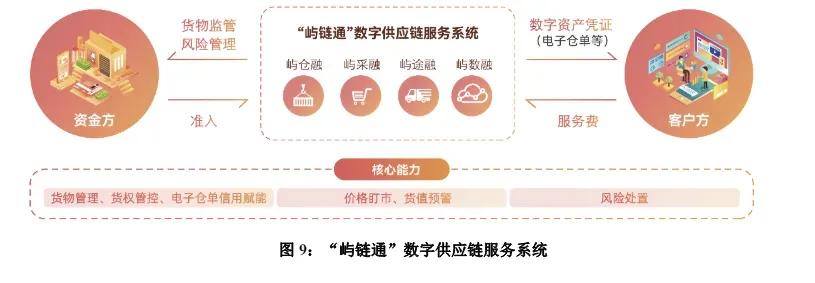
近日,国创资本“国创益链”供应链金融平台正式上线运行,并开具了首张电子债权凭证,由核心企业国创东高向其EPC总包方开出,用于支付光伏项目建设款。 今年内,包括长江产业集团、济南钢铁集团、新疆商贸物流(集团)有限公司等多家国企上线供应链金融平台,今天就来盘点一下5家国企龙头与他们各具特色的供应链金融。 01 厦门象屿:综合性的大宗贸易供应链金融服务平台。 厦门象屿集团有限公司,是厦门市属国有企业,成立于1995年11月28日。旗下拥有投资企业400余家,全资及控股企业300余家,员工超万名。 象屿集团作为供应链领域的领先企业,一方面,基于自身供应链贸易场景,打造了“屿链通”数字供应链金融服务平台;另一方面成立象屿金控,并通过旗下象屿保理等开展供应链金融业务。 象屿股份开发的“屿链通”数字供应链金融服务平台,目前已推出“屿采融、屿仓融、屿途融”等产品,与多家金融机构完成系统对接,并实现了区块链电子仓单质押融资业务落地。 截至2024年6月末,屿链通”平台合作金融机构超10家,累计取得专项授信121亿元,累计助力客户完成超55亿元融资。 02 广西北投集团:广西首个由核心企业搭建的供应链金融服务平台。 广西北部湾投资集团有限公司(简称“北投集团”)是广西壮族自治区人民政府直属的大型国有独资企业,由原北投集团与广西新发展交通集团于2018年9月重组成立。 2022年2月,公开信息显示广西北投供应链就供应链金融系统进行招投标,中标人为广西北投信创科技投资集团,资料显示,本次供应链金融系统建设的内容包括数字化应收账款账款凭证(多级流转)、供应链资产证券化等。 2022年3月29日,北投供应链公司数字债权凭证产品“北链信”上线,3月31日,北投供应链公司成功为广西路桥集团供应商—广西某建筑工程有限公司开具了首笔“北链信”。据了解,该平台或是广西首个核心核心搭建并运营的供应链金融服务平台。 平台自2022年试运营至今,已累计为超过50家中小微企业提供融资服务,累计融资总额突破2亿元大关。 03 四川省投资集团:具有特色的票据撮合服务平台 四川省投资集团有限责任公司(简称“川投集团”)成立于1988年10月,是四川省委省政府批准首批组建的省级大型投融资运营公司和国有资本投资公司改组改革试点,是四川省国有资本授权经营主体、重点建设项目融资和投资主体之一。 2018年10月,川投集团旗下川投信息产业集团有限公司发起设立四川川投云链科技有限公司(以下简称“川投云链”),川投云链注册资本3.5亿元,是川投信息产业集团有限公司控股的省属国有金融科技平台企业。 川投云链以落实普惠金融、促进产业链发展为己任,是四川省内首家取得成都市金融局批准的票据经纪、票据中介、票据信息服务许可的供应链金融综合服务企业;成都市金融局首批次认定的金融科技企业。 川投云链自研产融数字新基建平台–“撮合拍供应链金融智慧服务平台”,推动数字技术、数据要素与金融服务在产业场景层面紧密融合。目前,撮合拍平台已直连建行、工行、交行、邮储、农行等20余家金融机构系统,平台对接的普惠资金体量更充裕、成本更低。同时与担保、保理、小贷等类金融机构创新合作模式,业务响应更迅速、方式更灵活。 04 华发集团:特色城市运营供应链金融服务平台 珠海华发集团有限公司组建于1980年,是珠海最大的综合型国有企业集团,华发投控通过旗下华发供应链金融、华金保理等开展供应链金融创新业务。 华发集团旗下华发供应链公司作为广东省供应链金融“监管沙盒”第一批试点企业,致力于通过科技手段推动商业信用价值传递,提高核心企业产业链上下游中小企业融资可得性。通过运用大数据、区块链、互联网等先进科技手段,成功搭建华发供应链金融平台。 2022年5月31日,华发供应链金融携手上海银行成功为珠海某教育服务公司开立近百万元的“粤融易”数字债权凭证,华发供应链金融全面开启“数字债权凭证+银行普惠资金”全线上化、批量化、实时化服务。 截至2023年1月,已累计帮助近1100家客户融资超105亿元,累计完成4400余笔业务投放,其中中小微企业占比94%,平均每笔融资金额约228万元。 05 上汽集团:国有背景的整车制造供应链金融服务平台 上海汽车集团股份有限公司作为国内规模领先的汽车上市公司,向为消费者提供移动出行服务与产品的综合供应商发展。 2020年5月,上汽集团金融板块下的金控管理有限公司,与上汽安吉物流联合注册成立上汽安吉商业保理公司。据了解,该保理公司成立后,将依托上汽的汽车产业资源,为集团供应链企业提供融资服务,协助集团提供综合的供应链金融服务。 同时,上汽孵化成立赛克供应链平台。该平台以核心企业信用为背书,以真实贸易背景为基础,以区块链底层技术为保障的供应链科技服务平台。平台旨在通过延伸核心企业的信用,为供应链上下游企业提供高效、经济、便捷、安全的 “供应链金融服务,实现“多赢”。2022年6月28日,农业银行与上汽赛克供应链平台成功对接,专属线上供应链产品——“保理e融”正式上线。 上汽集团自建供应链金融平台“安吉链”,致力于为供应商提供更便捷高效低成本的融资解决方案。 05 山东高速集团:首个千亿供应链票据平台 山东高速集团(简称“山东高速”)是山东省基础设施领域的国有资本投资公司,注册资本459亿元,资产总额突破1万亿元。 2024年1月,山东高速迎来首个自建电子债权凭证供应链金融平台-山高E信产融数字平台正式交付。该平台于2023年12月完成系统验收交付并进入平稳运行阶段。 多年来,山东高速集团及其旗下的多个公司积极探索供应链金融业务,并上线了速链云、高速e融、通汇资本供应链科技等多个多个供应链金融平台。 2020年,由山东高速股份自主研发的供应链金融平台“速链云”上线,这是山东高速集团首个自主研发的区块链多级拆分流转平台。2022年7月,山东高速股份对“速链云”平台进行了全新升级。升级后的“速链云+”在原有平台基础上,重构供应链金融信用基础,并与十多家银行实现全线上化、数字化、自动化系统的直连,通过搭建起 “资金超市”,可为平台用户提供一站供应链金融服务。 2021年10月,由山东高速集团旗下山东高速物流自主开发的“高速e融”供应链金融综合服务平台首笔业务测试落地,标志着全国高速运营行业首个物流供应链金融服务平台正式上线运行。 “高速e融”平台以区块链技术体系为基础,可为供应链平台提供分布式账本、智能合约、隐私保护、溯源防伪等多方面数据安全保障。同时,平台通过“物联网技术+AI识别+深度学习”,对货物状态实时监管,解决智能控货问题,解决传统仓单质押中虚开仓单、重复质押等痛点问题。 为推动供应链票据支付,山东高速旗下通汇资本搭建并运营了供应链科技平台,截至目前该平台已发展成为行业领先的供应链票据平台之一,这也是首个获准接入上海票交所的地方国企供应链金融平台。该平台可为大型央国企、政府平台、事业单位提供规范有效的数字化支付工具。实时展现全链路的各级支付情况。 2024年5月24日,通汇资本供应链票据平台宣布平台业务规模突破千亿。据了解,这或是首个供应链票据规模突破千亿的平台,也是用时最短突破千亿的供应链票据平台。 海量资讯、精准解读,尽在新浪财经APP