AI医师助手
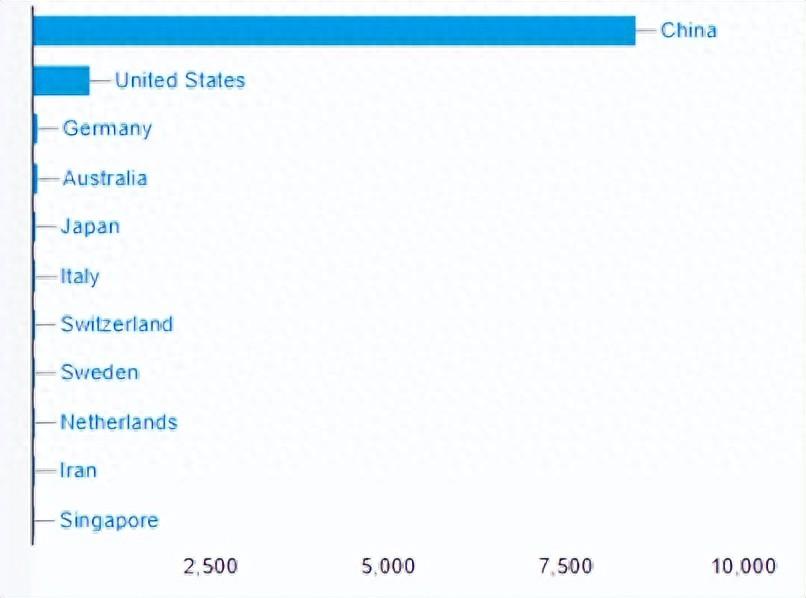
ChatGPT 回复: 再生医学研究是一门致力于利用细胞、组织工程和生物材料等技术来修复、再生和替代受损组织和器官的科学领域。它的目标是通过促进人体内在的自我修复能力,治疗和恢复各种退行性疾病、创伤和器官功能失调等病症。再生医学研究的几个主要方向: 1.细胞治疗:细胞治疗通过注射活性细胞或植入细胞载体来修复和替换受损组织。这些细胞可以是干细胞、多能性细胞或成体细胞,通过分化为特定细胞类型,提供细胞因子或刺激机体自我修复。 2.基因治疗:基因治疗旨在通过引入、修改或调节基因表达来治疗疾病。该方法可以修复遗传缺陷、增强细胞功能,或提供特定蛋白质以加速组织再生。 3. 组织工程:组织工程是使用生物材料和细胞培养技术创建可移植的人工组织。这些人工组织可以在受损部位重建功能,如人工血管、人工肝脏和人工皮肤等。 4. 人工器官:人工器官是用来代替或辅助受损或缺失的器官的医疗装置。通过使用细胞和生物材料技术,人工器官可以重建和恢复身体各个系统(如心脏、肾脏、胰腺等)的功能。 5. 生物打印:生物打印是一种先进的技术,可以将生物材料和细胞精确地按照设计的三维结构进行打印。这项技术的目标是通过打印具有特定结构和功能的组织和器官,来替代受损或缺失的部位。再生医学研究涉及许多其他领域的交叉探索,如生物学、生物化学、材料科学、工程学等。研究人员正在努力开发新的技术和方法,以提高再生医学的效果和安全性。这些研究对于未来治疗疾病、延长寿命和提高生活质量具有重要意义。 论文分析 检索数据库:Medline 检索工具:文献鸟/PubMed 检索时间:December 11, 2023 检索词:regenerative medicine AND China[ad] 中国再生医学研究论文发表的时间分布 中国再生医学领域研究已经发表了19181篇Medline收录的文献;文献鸟对最新收录的9998篇文献进行了分析。 国家分布可以看到,中国作者独立发表的文章数为8506篇,文章数占总量的85.1%;中美作者合作发表的文章数为816篇,占8.2%;德国、澳大利亚和日本是与中国作者合作发表较多的国家。 学术机构排名 中国浙江大学发表的再生医学研究文章最多,为398篇,学术影响力4024.8;其次为南方医科大学(314篇)、四川大学(298篇)、中南大学(233篇)、动物研究所(198篇)、同济大学(190篇)、暨南大学(164篇)、东华大学(144篇)、上海交通大学医学院(136篇)、香港中文大学(131篇)、西安交通大学第一附属医院(119篇)、广州医科大学附属口腔医院(114)篇、东南大学(101篇)等大学发表的论文较多。 医院排名 中国发表再生医学研究较多的医院中,南方医院发表的文章数量最多,为176篇。其次为上海东方医院(168篇)、华西医院(146篇)、湘雅医院(142篇)、西安交通大学第一附属医院(118篇)、上海市第九人民医院(114篇)、广州医科大学附属口腔医院(114篇)、华西口腔医院(111篇)、邵逸夫医院(107篇)、广西医科大学第一附属医院(90篇)、浙江大学第一附属医院(68篇)、同济医学院附属协和医院(68篇)、血液研究所和血液病医院(64篇)、珠江医院(63篇)、南京鼓楼医院(54篇)等是发表再生医学论文较多的医院。 发表的期刊 发表中国再生医学领域稿件数量较多的期刊有Front Cell Dev Biol (IF=5.5)、Front Bioeng Biotechnol (IF=5.7)、Nat Commun (IF=16.6)、Stem Cell Res Ther (IF=7.5)、Bioact Mater (IF=18.9)、Int J...