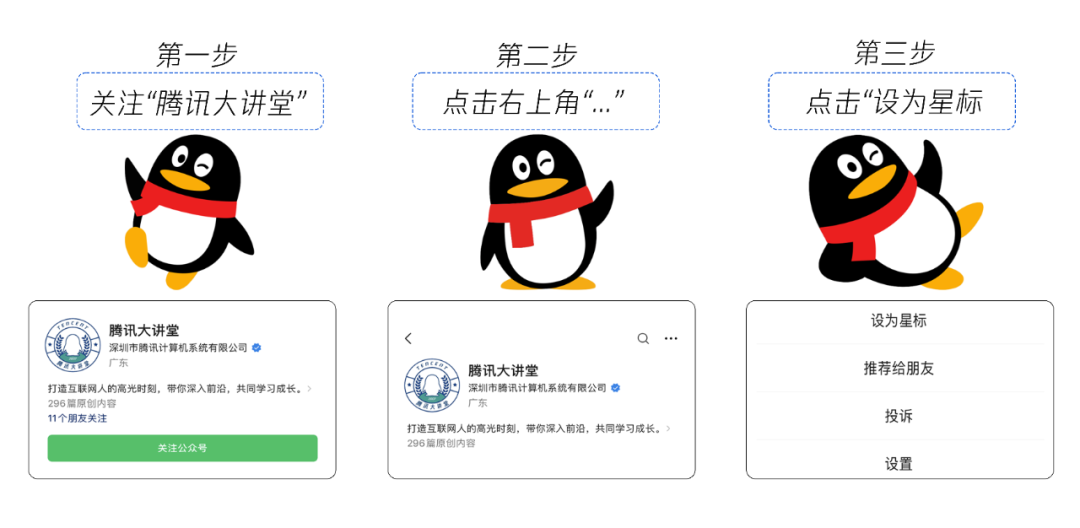
AI助手资讯
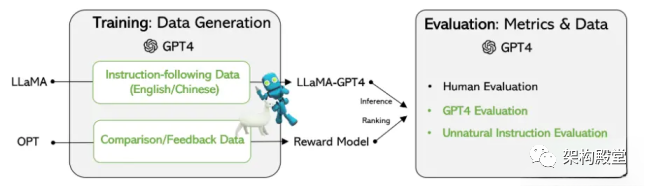
前言 对于我们目前的Chatgpt,如何能更有效的为自己或者公司生成个性化的数据是非场重要的,指令集对个性化定制使用Chatgpt至关重要,因为不同的用户有各自的偏好、需求和习惯,他们期望从Chatgpt得到的结果也会不同。定制化的指令集可以帮助用户根据自己的需求进行优化和限制,提高Chatgpt的效果。 例如,在一个医疗领域的Chatgpt模型中,有些用户可能更关心疾病的治疗方案,而另外一些用户可能更关心预防和健康维护方面的信息。针对不同的用户,我们可以定制专属的指令集,让Chatgpt更好地适应他们的使用习惯和需求,提供更贴合个性化的服务。 除此之外,个性化定制使用Chatgpt的指令集还可以减少用户学习和使用Chatgpt的成本,简化操作流程,提高使用效率。 而且(Instruction)是ChatGPT模型取得突破性进展的关键因素,可以让语言模型的输出更符合「人类的偏好」。 但指令的标注工作需要耗费大量的人力,即便有了开源的语言模型,资金不足的学术机构、小公司也很难训练出自己ChatGPT. 最近微软的研究人员利用之前提出的Self-Instruct技术,首次尝试使用GPT-4模型来自动生成语言模型所需的微调指令数据。 在基于Meta开源的LLaMA模型上的实验结果表明,由 GPT-4生成的5.2万条英语和汉语instruction-following数据在新任务中的表现优于以前最先进的模型生成的指令数据,研究人员还从GPT-4中收集反馈和比较数据,以便进行全面的评估和奖励模式训练。 训练数据 数据收集 研究人员重用了斯坦福大学发布的Alpaca模型用到的5.2万条指令,其中每条指令都描述了模型应该执行的任务,并遵循与Alpaca相同的prompting策略,同时考虑有输入和无输入的情况,作为任务的可选上下文或输入;使用大型语言模型对指令输出答案。 在Alpaca 数据集中,输出是使用GPT-3.5(text-davinci-003)生成的,但在这篇论文中,研究人员选择使用GPT-4来生成数据,具体包括以下四个数据集: 英文Instruction-Following Data:对于在Alpaca中收集的5.2万条指令,为每一条指令都提供一个英文GPT-4答案。如下代码 Algorithm 1: Pseudo code for prompt engineering, GPT-4 call and hyper-parameters in datageneration. Each instruction instance is used as variables in the prompt template, the data flow ishighlighted in blue.1...