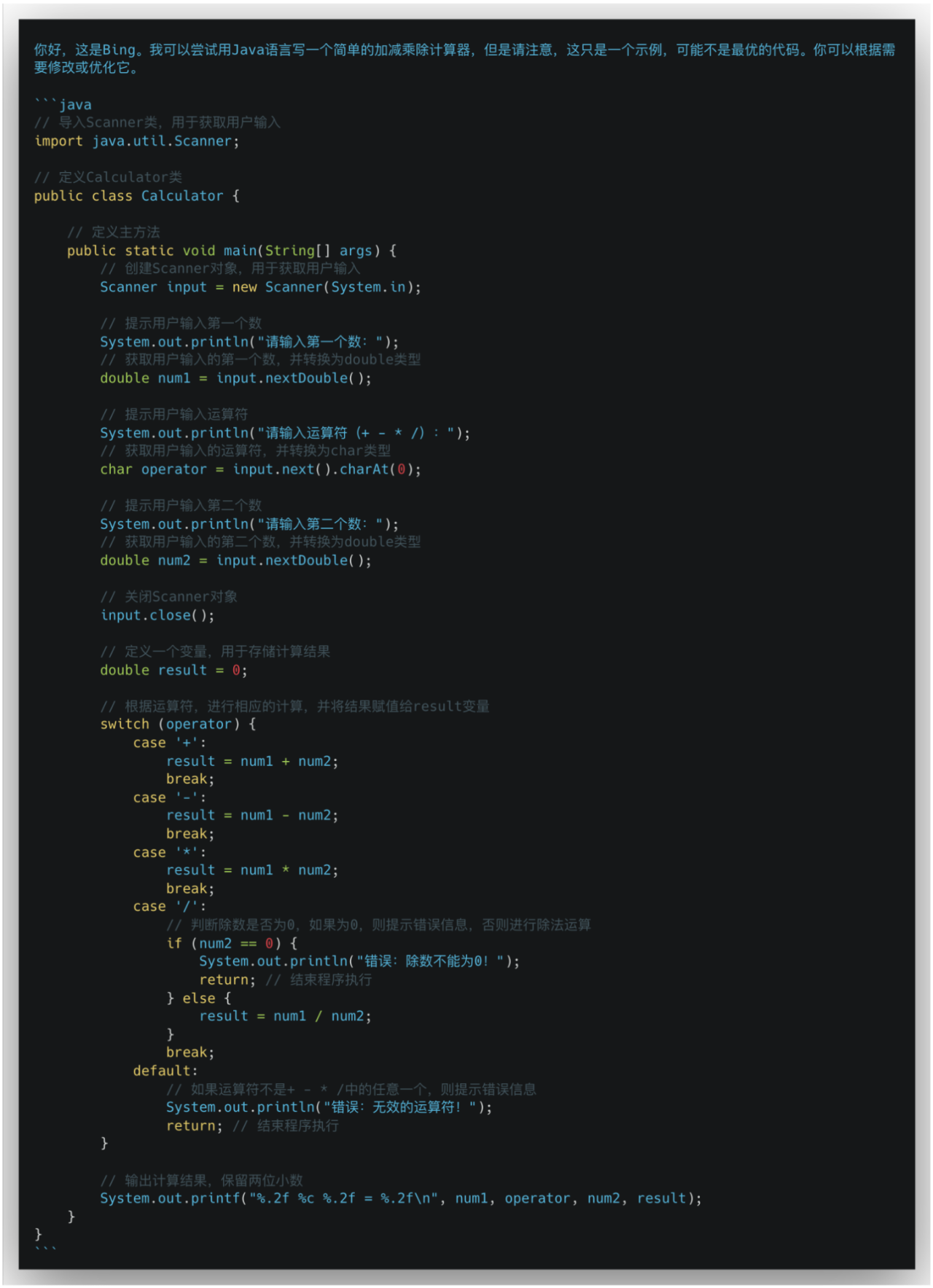
AI助手资讯
上一篇文章我已经删除,因为那个时候我才初步接触AI绘画,对于绘画提示词不是很了解,生成的图片也不是很好看,所以这几天我又在网上学习了一下关于AI绘画提示词的描述,下面的内容是我从多个网站整合汇总的提示词。另外,SD的官网不知道为什么登不上去了,我现在换成用open AI来绘图了。 一、画质提示词 – masterpiece- 产生大师级艺术品的提示。 – best quality- 确保最佳图像质量的提示。 – high resolution- 生成高分辨率图像的提示。 – 8k- 生成比 4K 分辨率更高的图像的提示。 – HDR- 生成具有高动态范围的图像的提示。 extremely detailed CG unity 8K wallpaper (超精细的8K Unity游戏CG) unreal engine rendered (虚拟引擎渲染) 示例:起手式输入下述提示词,生成图片质量就会提高。 best quality, ultra-detailed, masterpiece, finely detail, highres, 8k wallpaper 二、背景篇 gradient...